This page explains the details of all the algorithms and methods used to develop models for prediction of Immunomodulatory Oligodeoxynucleotides (IMODNs).
|
|
Dataset
| Our data can be divided as: |
|
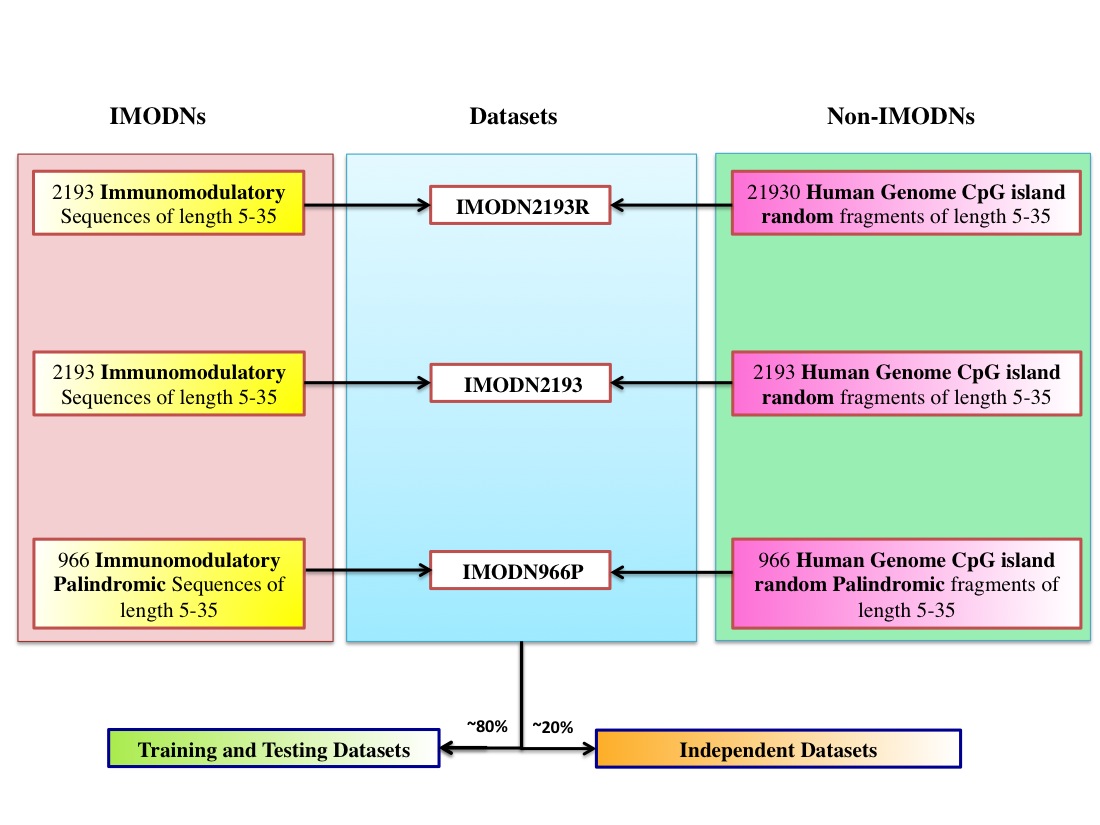
1. Main-balanced-dataset: IMODN2193 This includes 2193 sequences as positive sequences, 2193 negative sequences obtained from random fragmentation of the human genome CpG islands.
2. Main-Real-dataset: IMODN2193R This includes 2193 sequences as positive sequences, 21930 negative sequences (10 times the positive sequences) obtained from random fragmentation of the human genome CpG islands..
3. Palindrome-dataset: IMODN966P This includes 966 sequences from the positive sequences of the dataset IMODN2193 that contain palindromes as positive sequences, 966 negative sequences obtained from the palindrome sequences among the negative sequences in the dataset IMODN2193R.
|
Compilation of Datasets
Support Vector Machine based methods
In the present study, SVM classifier was used from freely available SVM_light packagg
e . This package is powerful as well as user-friendly where we can adjust the parameters and kernel functions like Linear, Polynomial, RBF and Sigmoid.
|
Evaluation or Performance
|
Five-fold cross validation technique has been used. Four sets are used for training and remaining one in used for testing, in this way the process repeats five times.
Evaluation of performance of different SVM modules has been done by calculating accuracy and Matthew's correlation coefficient (MCC).
|
Input features for SVM
| In this study we have been used various features as SVM input for the prediction of CPPs. |
|
1. Pentanucleotide Composition: Pentanucleotide Composition is the percentage value of each of the possible 1024 pentanucleotide sequences within a given query sequence. There are 1024 vectors generated in which each vector corresponds to one pentanucleotide and these vectors used for as SVM input.
2. MERCI motif: These are the motifs found using the MERCI software that are present in the postive sequences but not in the negative sequences or vice-a-versa. Only the top 20 motifs present in the positive sequences but absent in the negative sequences were taken into account for the purpose of prediction. If any of these motifs are present in the query sequence, the SVM score is increased +1.
|
|