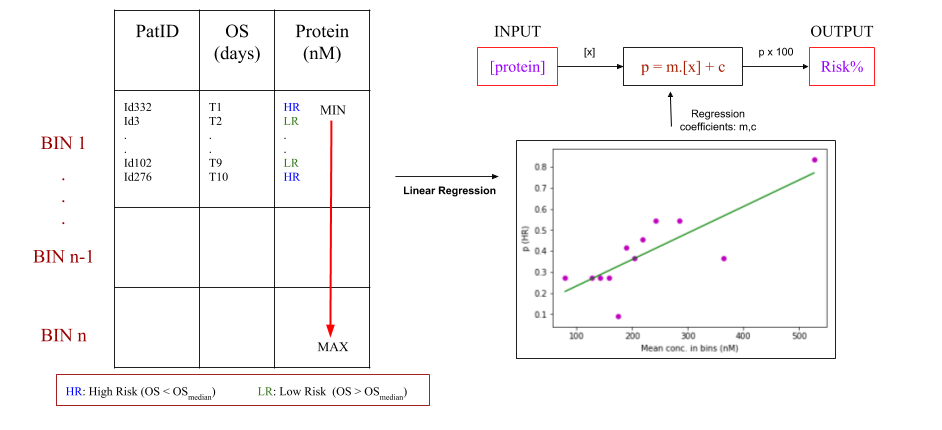
This web-server predicts risk in two modules, single protein- for each apoptotic protein under study and multiple proteins- for collective behaviour of all the proteins under study. Refer below section for further information:
Description
Single Protein This module computes the percentage of high risk against each selected protein separately. Initially protein concentrations in the dataset are labelled High Risk and Low Risk based on median survival time. This labelled dataset is then sorted, in an ascending concentration order, for each protein and divided into bins made by consecutive medians. Figure below explains the risk percentage estimation based on an input query concentration that fits into a specific concentration bin. Protein concentrations were normalized between 0-1 to handle non uniform data. This analysis is based on CRC stage III cohort data (see Datasets) since TCGA COAD protein concentration data was estimated using regression models.
Multiple Proteins
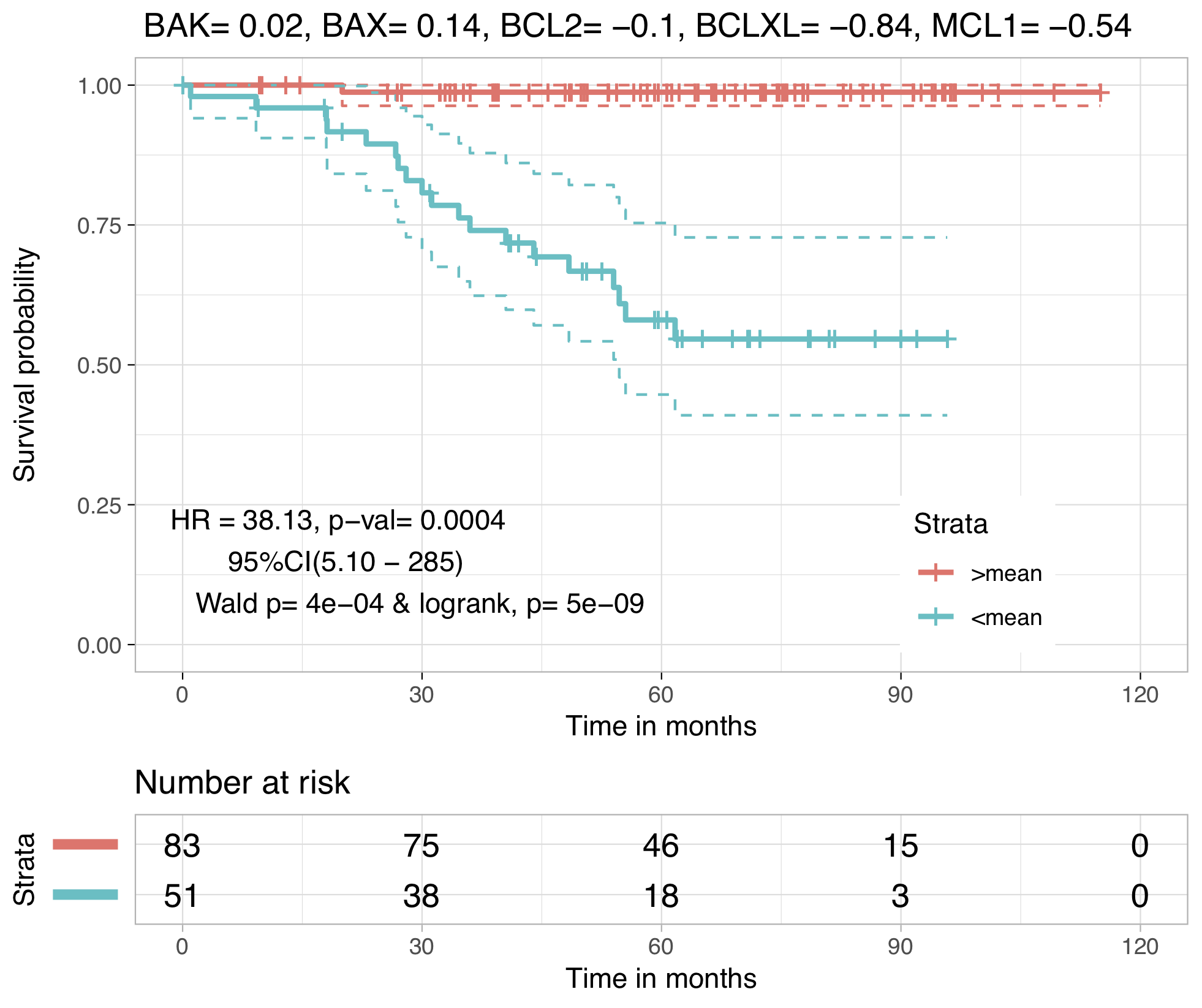
This module compoutes the risk score of patients given the concentrations of all five proteins by estimating β. Risk scores are calculated along with risk grade defined on the basis of whether β lies in the high risk group (β<mean(β)) or low risk group (β>mean(β)). This analysis is based on fitting the CRC stage III data in a cox proportional model with mean β as cutoff for dividing high and low risk groups. Following figures are KM plots with HR and CI values along with other statistical test results for CRC dataset: