Dataset information:-
The study was performed on the datasets taken from miRBase version 13.0. We retrieved 690 experimentally validated sequences of human miRNAs hairpin. These sequences were divided into two groups; (A) Training dataset: comprised of 555 sequences used for development of models. (B) Independent testing dataset: comprised of 135 sequences used to evaluate the performance of models.
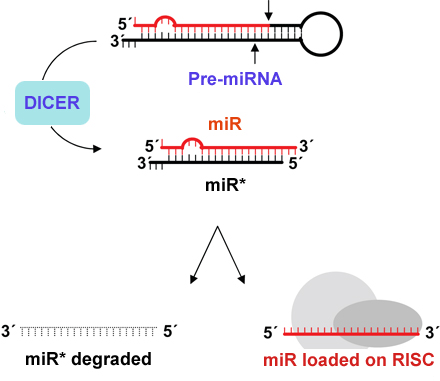
Dicer cleavage site:-
This algorithm extracts 14 nt long sliding structure pattern having cleavage site at centre and binary pattern were generated. It checks the score of cleavage site from 17 to 27 nt (miRBase 13) If the score of the sequence is more than exceeds the threshold the middle of the 14 nt is predicted as Dicer cleavage sites. The results may generate several cleavage sites with different SVM score and site given highest score is considered as most probable cleavage site. Each of result display format firstly provides name of sequence, structure pattern having cleavage site at centre followed by position of Dicer processing sites. Pattern display in descending order of SVM score that means pattern of highest score comes at the top.
Support Vector Machine:-
In this study, Support Vector Machine (SVM) models were developed using package SVM_light for predicting cleavage sites (Joachims, 1999).We used RBF kernel to predict the Dicer cleavage sites. We developed SVM models using binary pattern feature where a nucleotide was represented by a vector of dimension four (A by [1,0,0,0], C by [0,1,0,0], G by [0,0,1,0] and U by [0,0,0,1] 0 by [0,0,0,0]). Thus 14 nt structural Dicer cleavage pattern (having 14+14 nt) was represented by a vector of dimension 112. All models were evaluated using non-redundant five-fold cross validation technique.
Evaluation of Performance:-
The 5 fold cross validation technique examined the prediction quality. In this technique data is divided into five nearly equal sets, four sets are used for training and re maining set for testing. This process is repeated five times so that each set is used once for testing. Final performance is average performance on five sets. In order to create non-redundant dataset we create five sets in such a way that all pattern of a family in a single set. Standard parameters such as sensitivity, specificity, accuracy and MCC were used for evaluating all models developed in this study.
Sensitivity = TP / (TP+FN),
Specificity = TN / (TN+FP),
Accuracy= TP+TN/(TP+TN+FP+FN),
MCC = (TP * TN) - (FP*FN) / Ö(TP+FN)* (TP+FP)*(TN+FP)*(TN+FN).
True Positives (TP), True Negatives (TN), False Positives (FP) and False Negatives (FN).