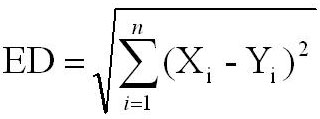|
| Co mposition based P rotein Id entification |
| |||
| H o m e | S e a r c h A l g o r i t h m | H e l p | T e a m | C o n t a c t |
| Search Algorithm |
|
Searching is basically based on the difference of composition between the two protein sequences. The composition can be in form of amino acid or dipeptide composition. During searching first composition of query protein(s) is calculated which is then search against the corrosponding composition of database proteins. The inference of relatedness is drawn on basis of Euclidian Distance (ED) between the two sequences. Lesser the ED, more related the two sequences are and vice-versa.
The processing of query protein occur in two ways.
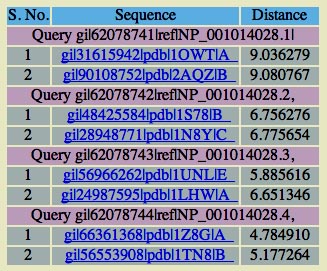
In the search result shown above, four proteins are used as query in BATCH MODE. For each protein top two hits i.e. two proteins with minimum ED are displayed. |