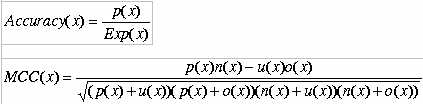|
Dataset Information
The dataset used in development of this server is same as previously used by Eklrod and Chou, (2003). Here is brief description of the dataset (for detailed description see Eklrod and Chou, 2003). All the sequences of dataset were unique and complete (sequence fragments are removed from dataset). After screening the number of sequences for octopamine and histamine were 10 and 6 respectively. They were not statistically significant so they were not considered. The final dataset consisted of 167 sequences, in which 31 are acetylcholine, 44 adrenoceptors, 38 dopamine and 54 serotonin type of receptors.
Support Vector Machine
In this study, SVM_light was used to implement SVM. The SVM was provided with input of fixed length vector obtained from proteins of variable length. The fixed length vector was obtained from proteins of variable length using amino acid and dipeptide composition.
i) Amino acid composition:
The amino acid composition provided the information of protein in 20 dimensions vector. The amino acid composition is the fraction of each amino acid in protein.
ii) Dipeptide Composition:
The dipeptide composition provided the information of protein in the form of a vector of 400 dimensions. The dipeptide composition encapsulates the information about fraction of amino acids as well as their local order.
Implementation of Prediction Method
The classification of an unknown protein into one of the four types of amine receptors is a multiclass classification problem. In this regard, a series of binary classifiers were developed, which predict only single type of amine receptors. Here, four SVMs one for each type of amine receptors were developed. The ith SVM will be trained with all samples of ith subfamily with positive label and all the samples of all other subfamilies as negative label. The SVM trained in this way were referred as 1-v-r SVMs (Hau and Sun, 2001). In such classification each of the unknown protein will achieve four scores. An unknown protein will be classified into the amine receptor type that corresponds to the 1-v-r SVM with highest output score.
Evaluation of Performance:- The performance of composition as well as dipeptide composition based modules developed in this method is evaluated using 5-fold cross-validation. In 5-fold cross validation dataset was randomly divided into five equal size sets. The training and testing of every module was carried five times, each time using one distinct set for testing and remaining four sets for training. The performance of each module is assessed by calculating the accuracy and Matthew's correlation coefficient (MCC).The formula's of acuuracy and MCC calculation are shown below.
Where x can be any type of amine receptor (Acteylcholine, Adrenoceptor, Dopamine and Seotonin) exp(x) is the number of sequences observed of type x, p(x) is the number of correctly predicted sequences of type x, n(x) is the number of correctly predicted sequences not of type x, u(x) is the number of under-predicted sequences and o(x) is the number of over-predicted sequences.
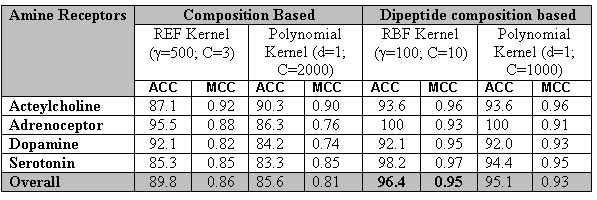
The performance of both amino acid and dipeptide based composition methods is shown below in tabular form.The average accuracy of the method based on amino acid composition and dipeptide composition is 89.8% and 96.4% respectively, when evaluated using 5-fold cross-validation.
|